Aaron is a multi-disciplinary designer with a focus on product design. With over 15+ years in the field, he’s had the opportunity to work with agencies, consultancies, in-house and non-profits but currently prefers helping out smaller start-up teams. Some previous experiences include IDEO, Google, R/GA, Frog, Verizon, Citi, GE, Betaworks and Instapaper.
At the moment he resides in California with his wife Tina and two parrots, Taco and Burrito.
aaronkapor@gmail.com
209.604.7702
About This Site
This site is an evolving work-in-progress with selected samples from current and past projects. Equal parts process and final deliverables, it’s meant to showcase thought patterns that are unique for each project in order to create a true variety of work. It was coded and compiled with Jekyll.
A complete update of Matter's feedback response flow based on the learnings gathered from sessions with users.
Matter’s original feedback response flow (FRF) was created to solve a very different problem than what we needed at the start of this project.
Matter is a service that allows professionals to send and receive quick feedback from their peers and collegues. Members are able to choose from an assortment of skills and set-up recurring feedback on a cadence of their choosing. Designing the feedback process was a fun challenge with many surprising obstacles – including the entirety of the covid pandemic.
The most noticeable issue was how many different elements there were, optically competing for attention.
The aim was to try and design a smooth and productive user experience – simplifying what we could and retaining some of the playfulness while at the same time incorporating the following considerations where appropriate.
Flow:
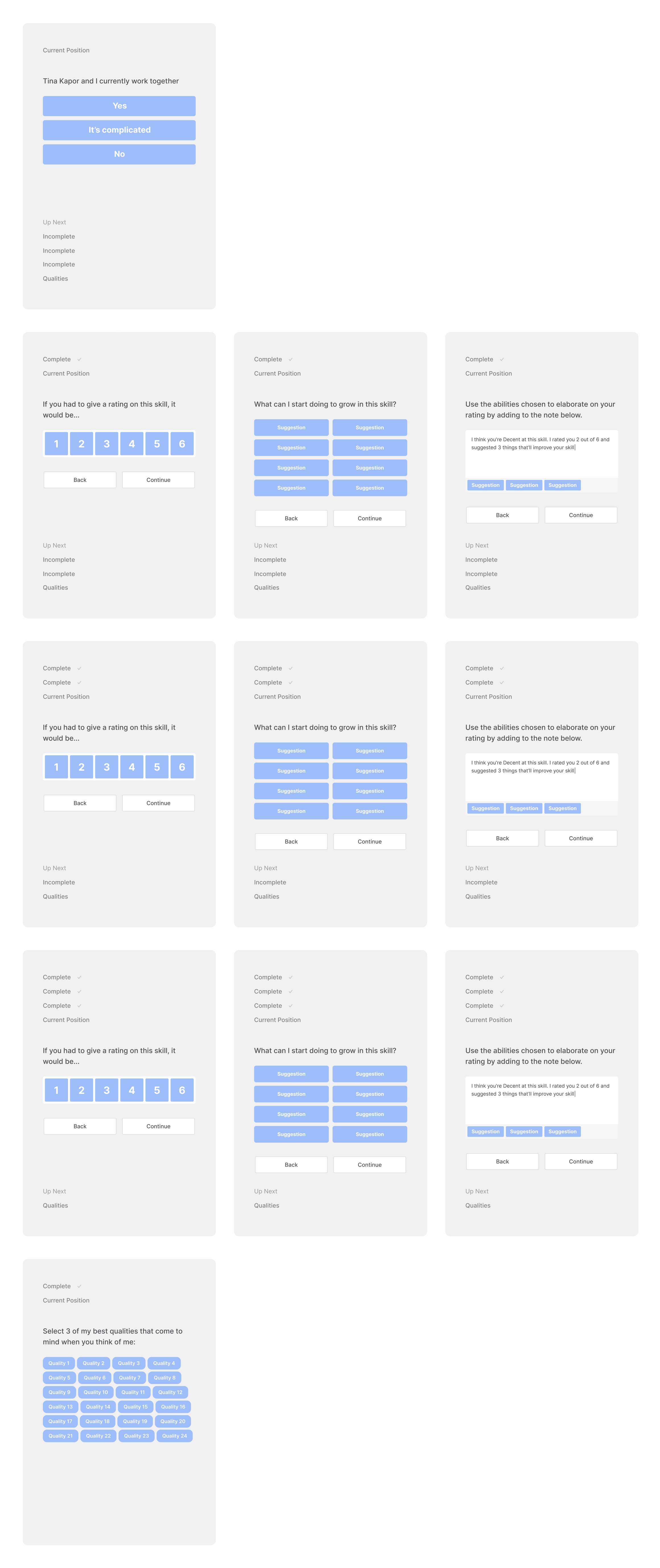
Givers are not clear of their progress (steps remaining in the flow).
Flow Card Navigation is painful on desktop when the action buttons are in the header.
Via Invite URL / Mobile auth requirement needs to go away.
Notes:
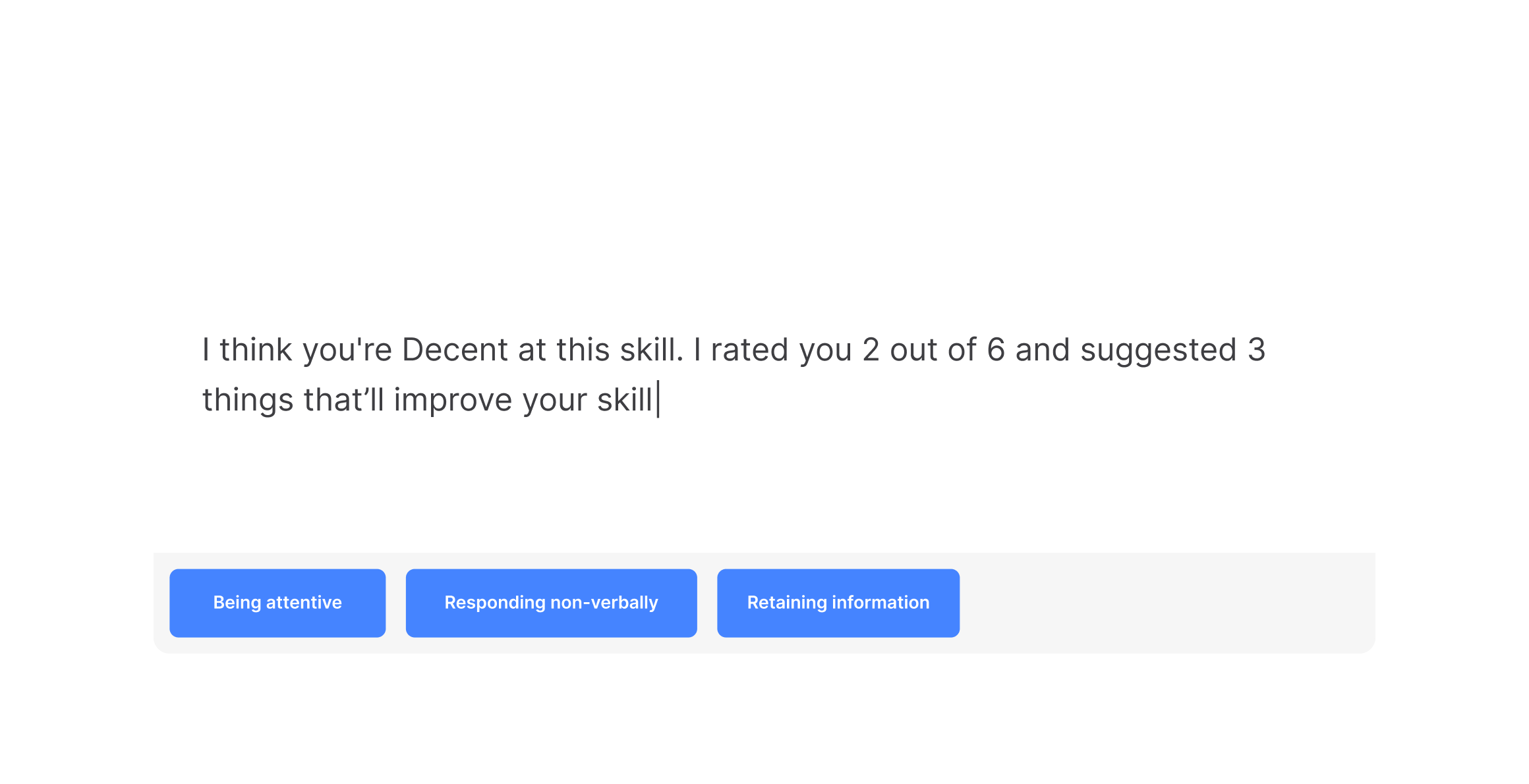
Customize your note: The text area does not grow.
Default notes / givers pressed on time would like more options.
Default notes / Receivers wish there was more emphasis on non-default.
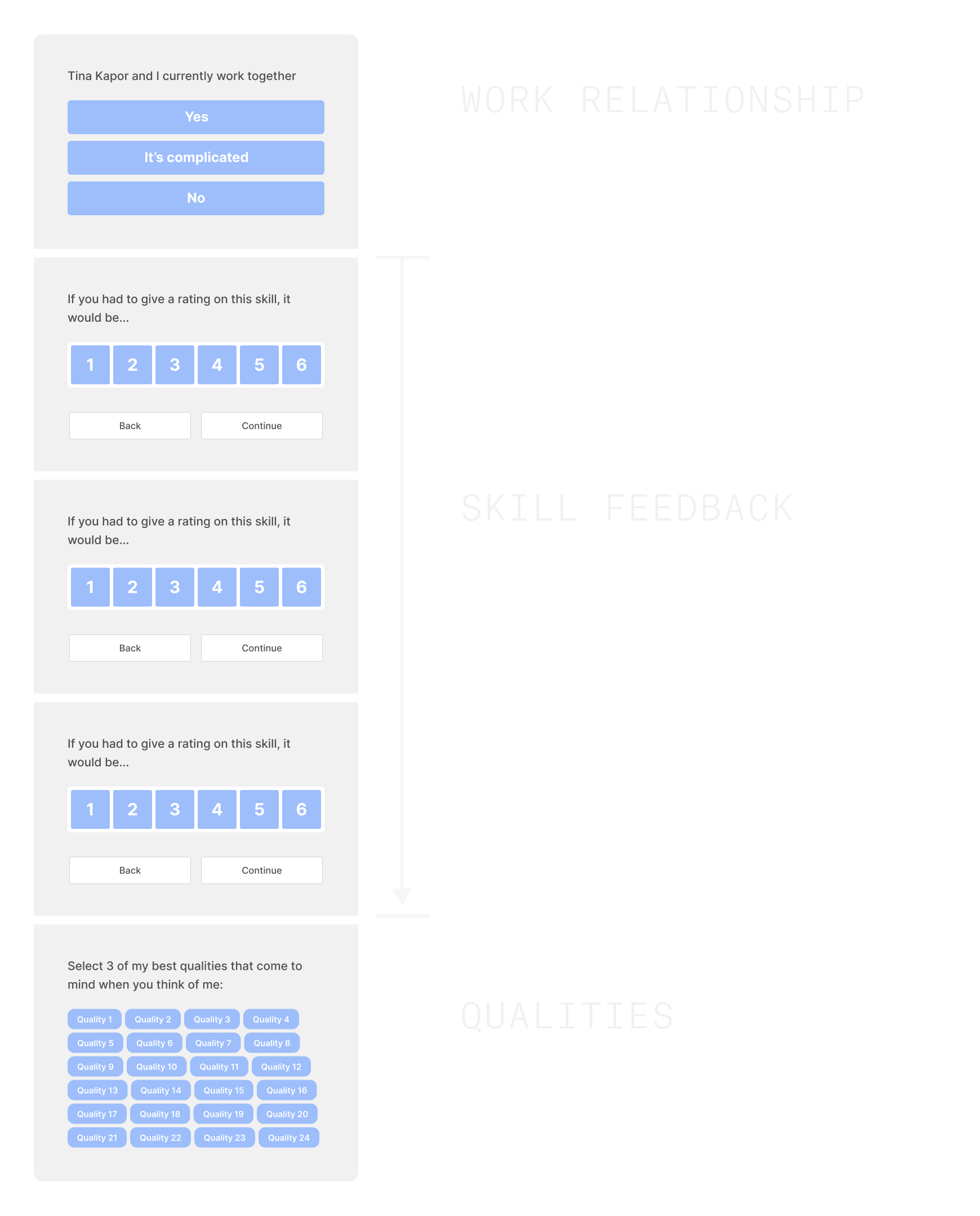
Rater:
Unclear number emoji association.
Variance in scale / how do givers and receiver align on what a 1 or a 10 looks like.
Leave a Note / 2 Steps Required.
Color association / is that helping or hurting us?
Abilities:
Why prompt for just 1 skill versus all.
Receivers would like a clearer link between note and abilities.
Receivers would like to use abilities to help align on rating scale.
The initial approach was to start playing with and leverage what was already in use – sometimes a simple adjustment can pay dividends. Elements such as the emoji’s (I wasn’t a fan of them) might even work in a different context.
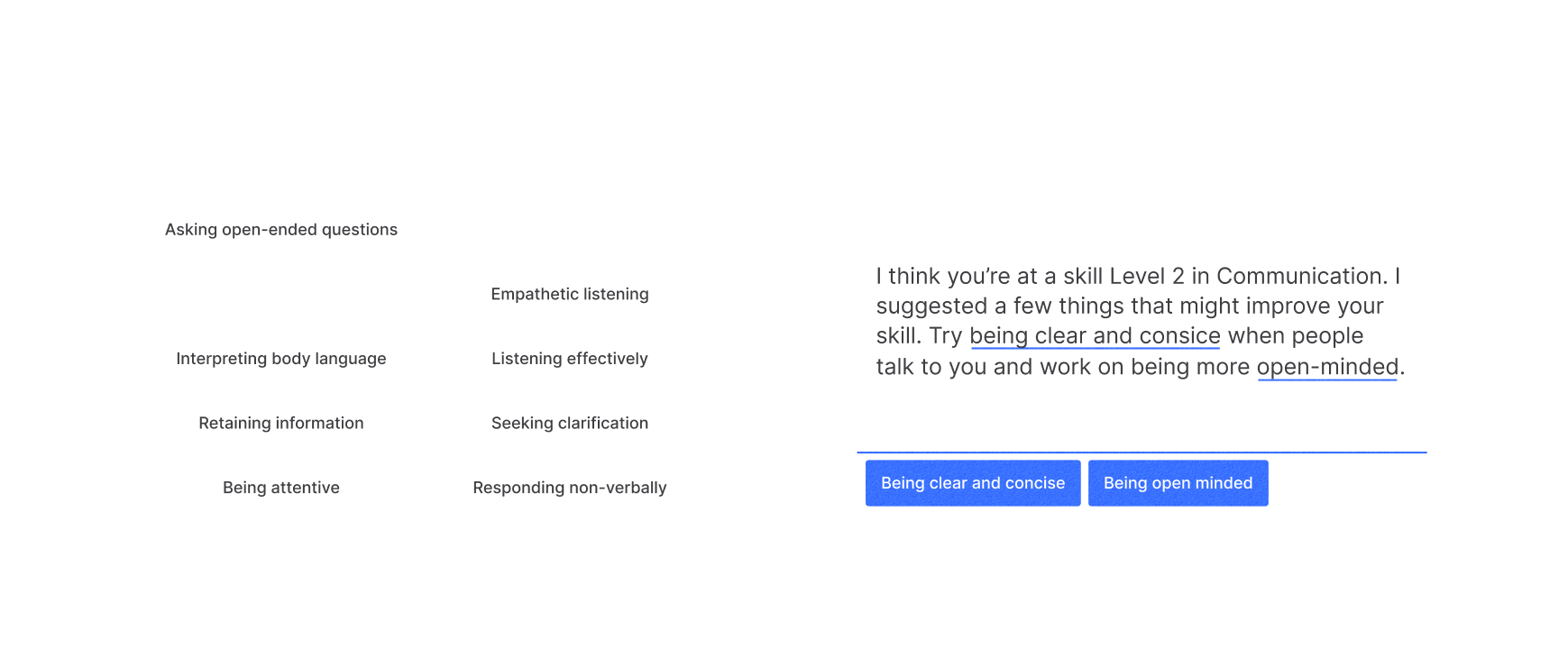
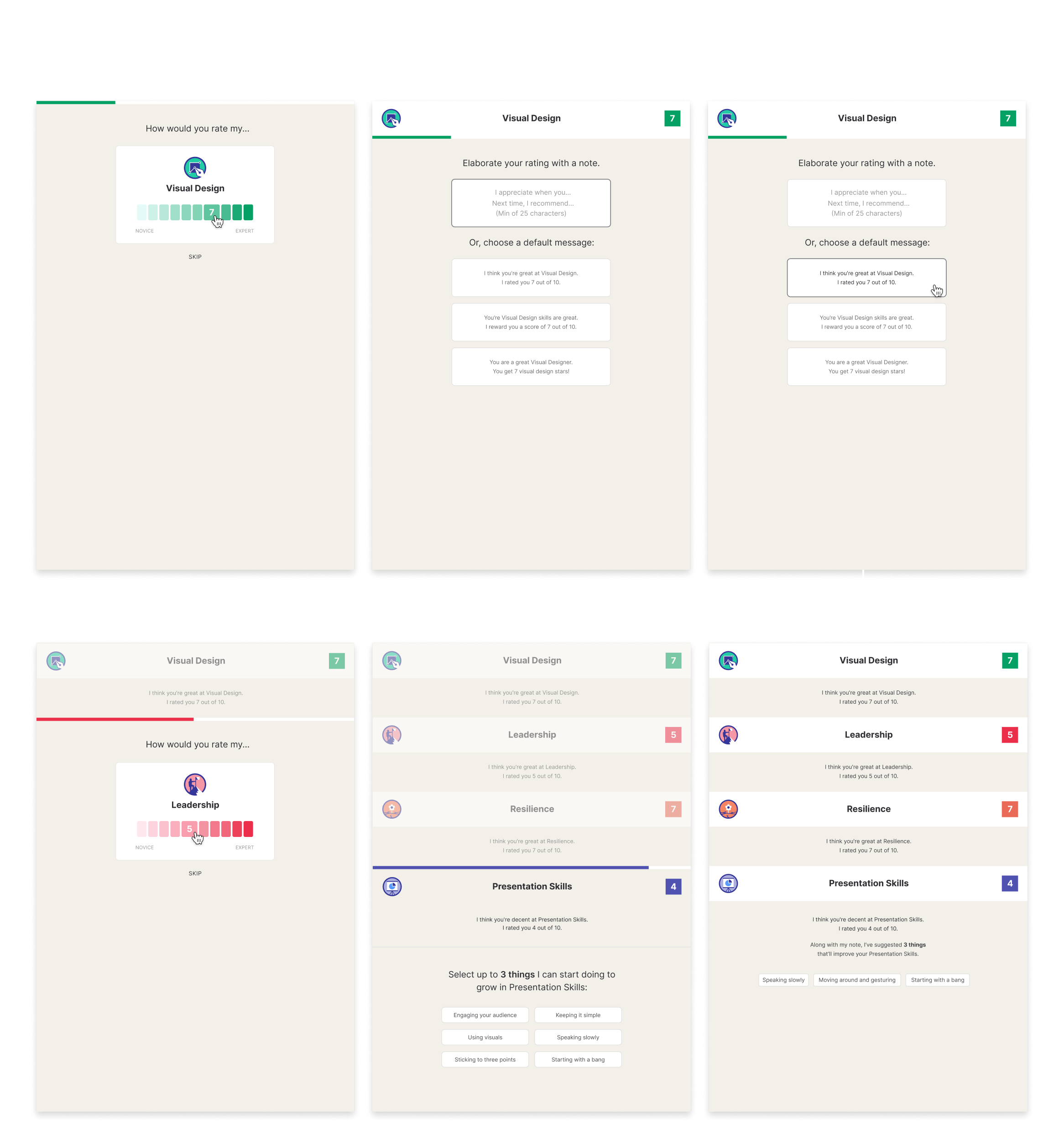
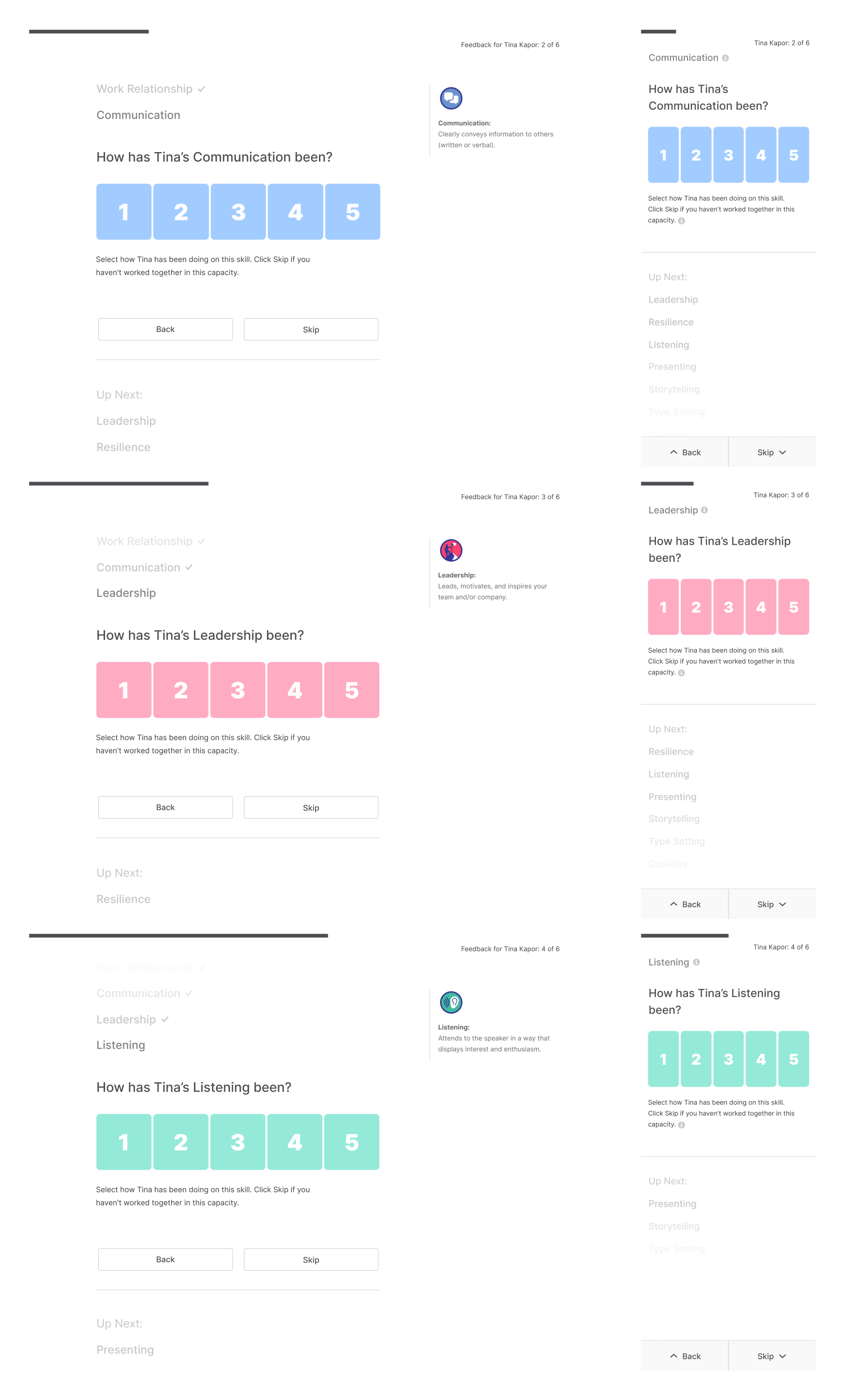
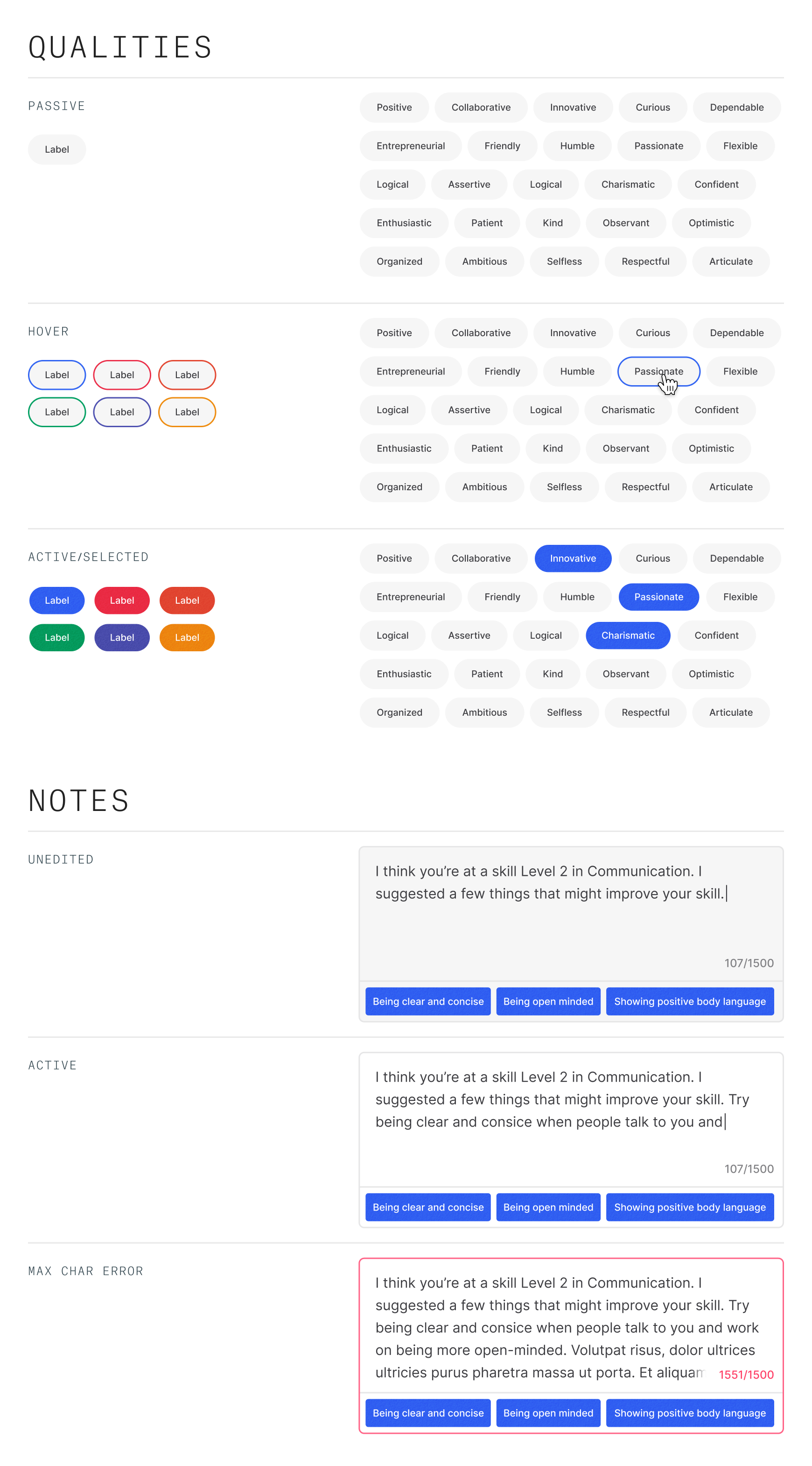
Something that seemed pretty easy to tackle was the feedback regarding abilities. Abilities are a collection of suggestions that relate to specific skills. Each skill has their own set and they are meant to help round everything out with attainable action items.
In the previous iterations, we only prompted the giver to add these for one skill, in the rest of the work going forward we decided to prompt them for every skill. The reasoning being that the effort for selecting 3 pre-defined options is minimal – hopefully limiting any kind of drop-off.
We also wanted to these chosen abilities to help guide the note – solving for the link between the two. We found a way to add them to message box.
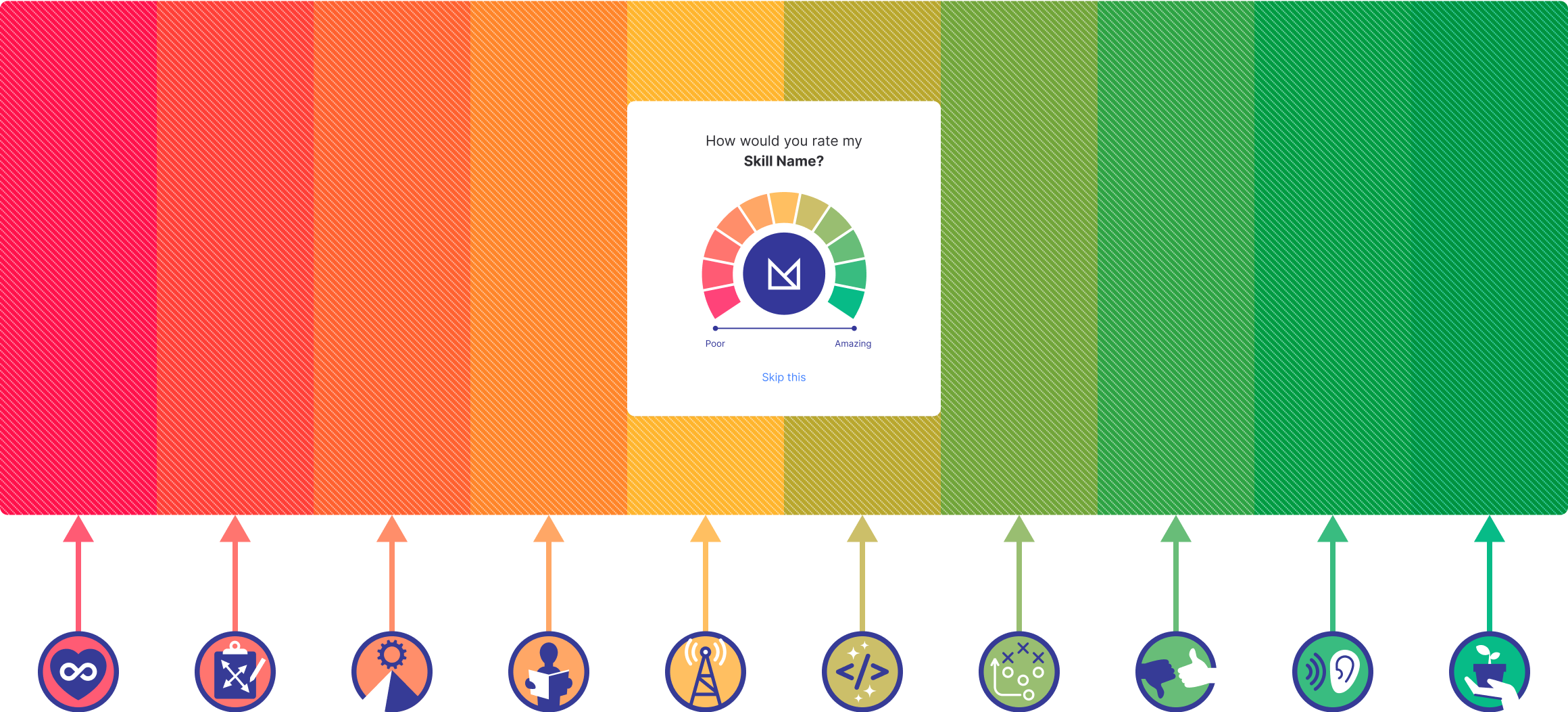
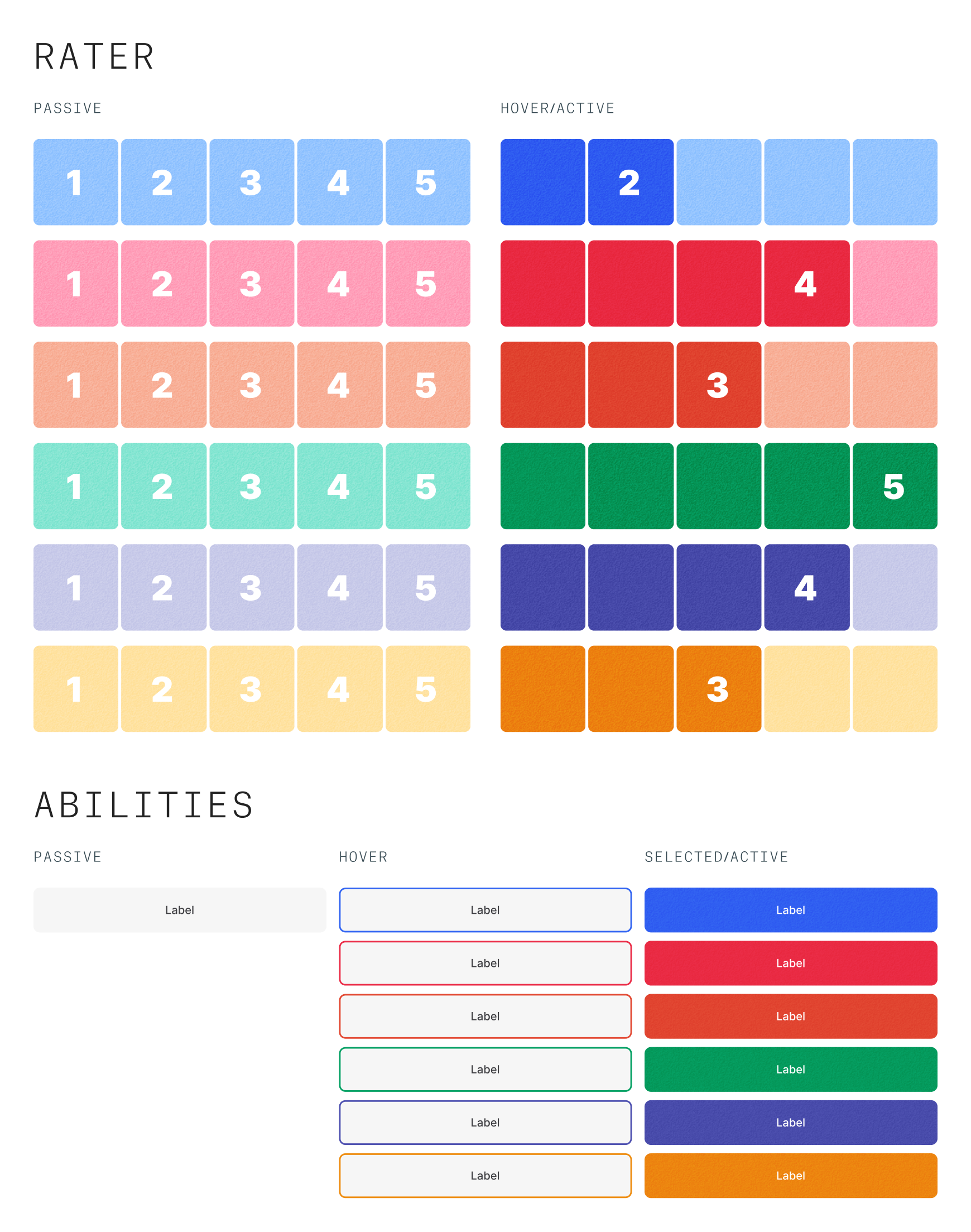
One of the areas of concern for me was the rainbow colored wheel. The fact that skill badges were arbitrarily using the same colors only added confusion and could create a number of unknown biases towards certain skills.
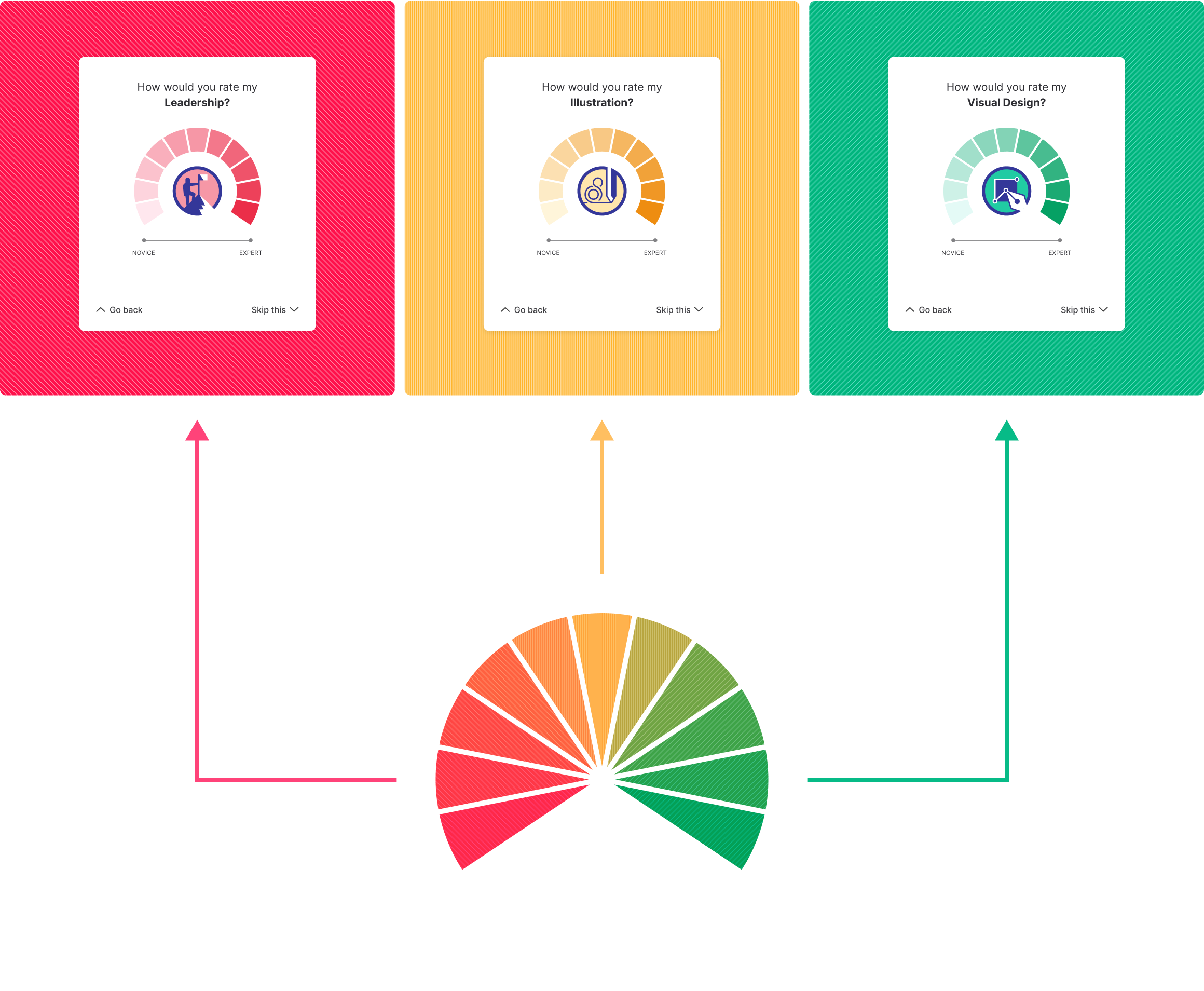
An obvious idea that was thrown out there was just to color code the skill rater with whatever color the skill badge had. So instead of red=bad, red equals the skills that match that color (leadership, etc.).
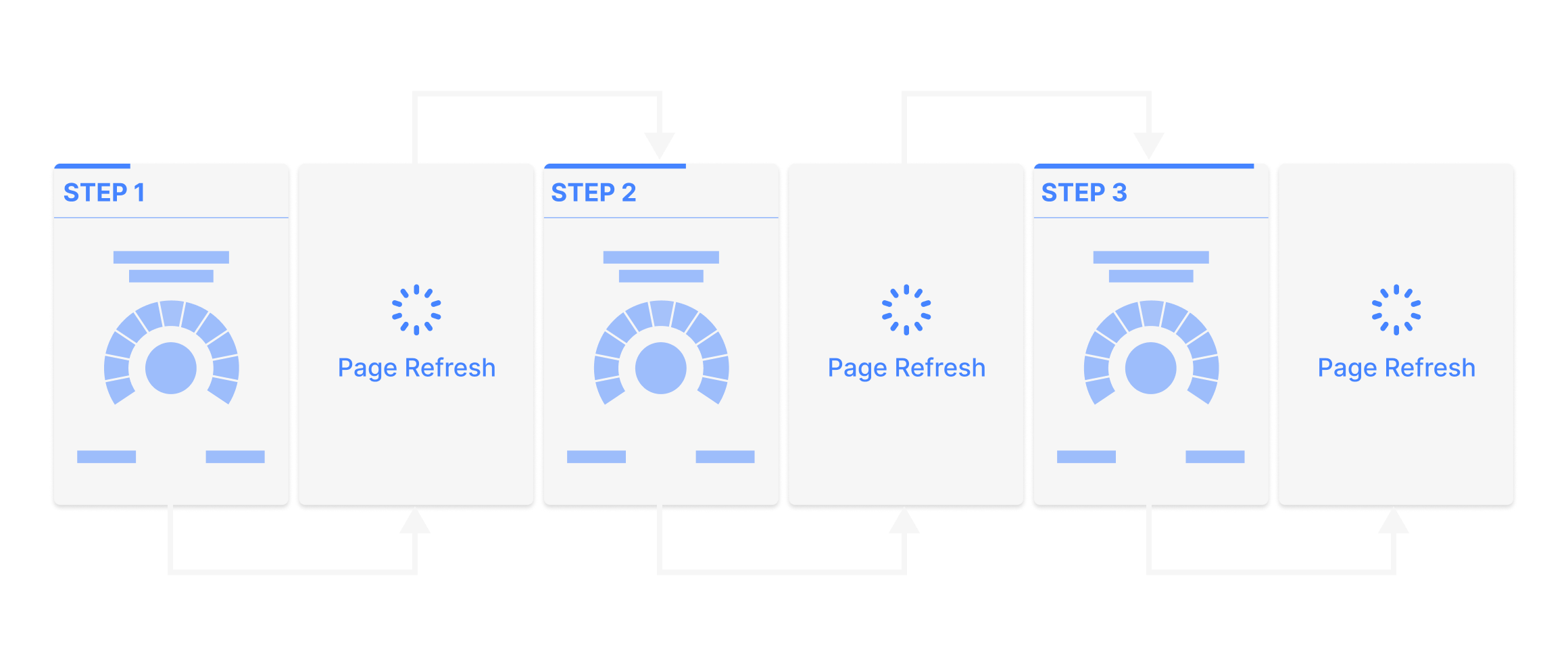
Another issue was the apparent page refresh between skills that the flow cards conveyed. To the user it really made everything move much slower.
One idea was to vertically stack them on the same page and auto-scrolling the user would be a much more efficient experience. Similar to the “build-as-you-go” flow that made Typeform so popular.
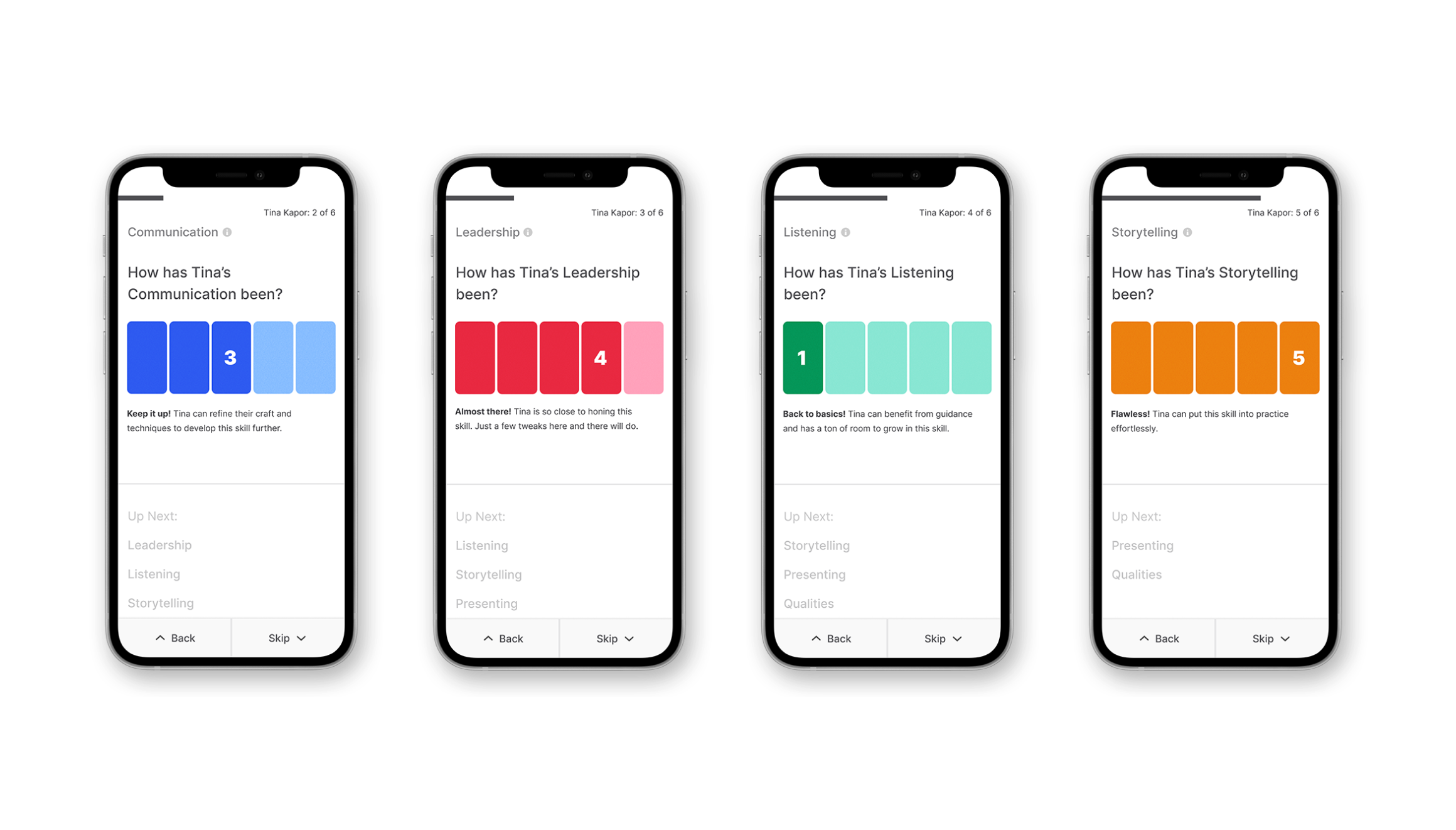
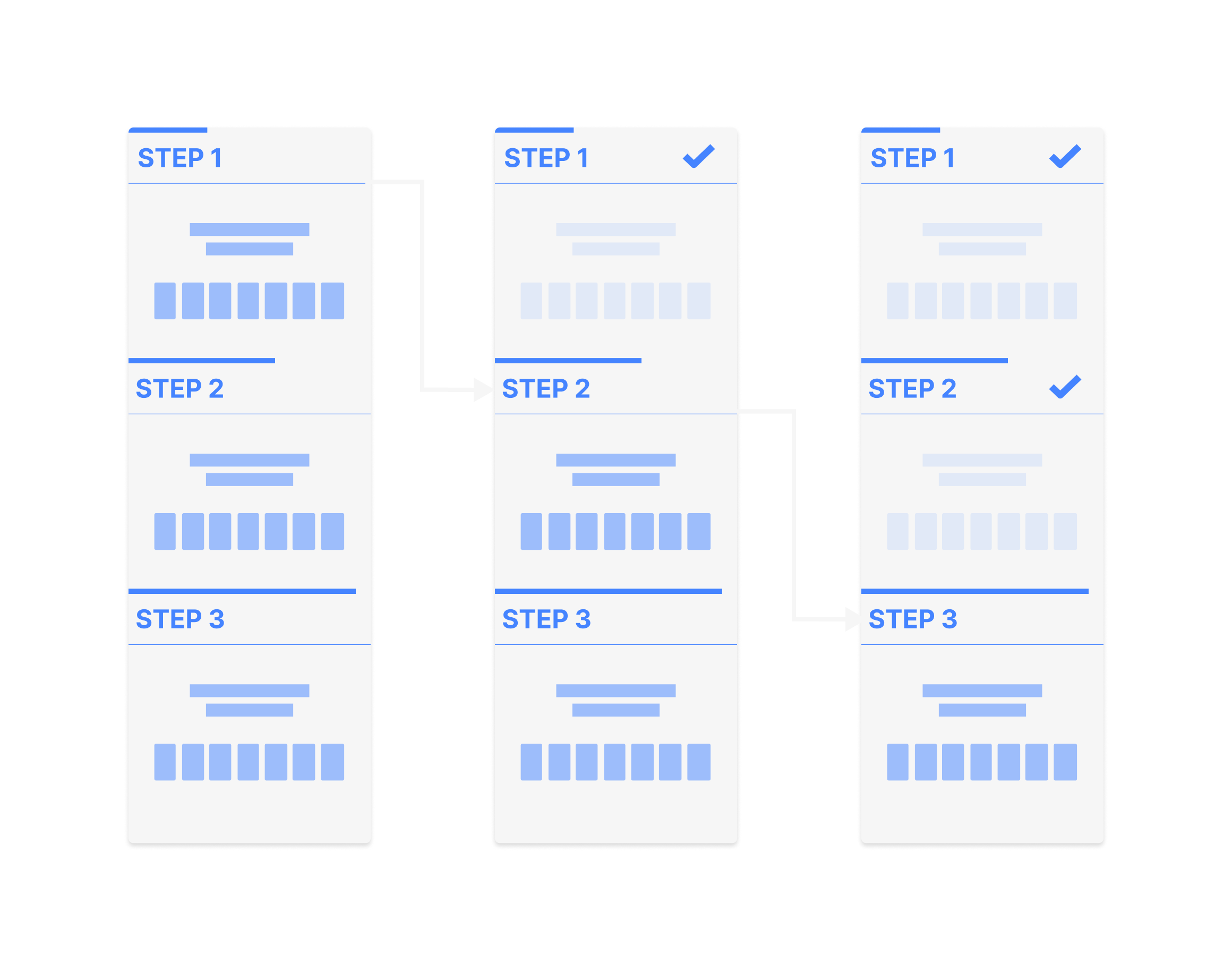
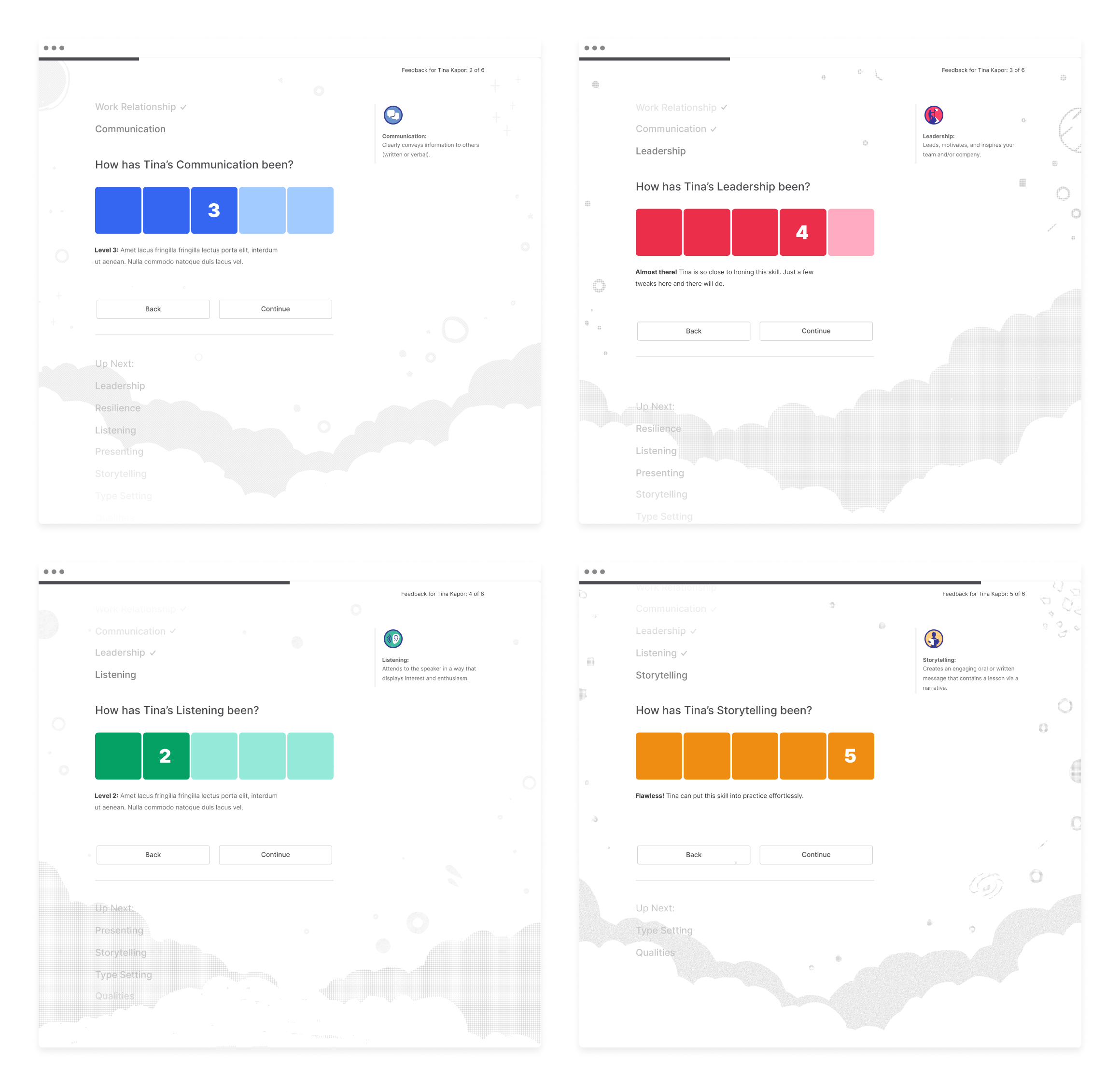
After many variations, the flow was simplified to the following structure.
Since there’s more in-depth feedback nested into each one of the skills, we needed a way to partition them into sub-steps without overwhelming the giver. So we went with a horizontal array-sequence within each skill (down-right-right-down-right-right-etc.)
And the above framework with some content.
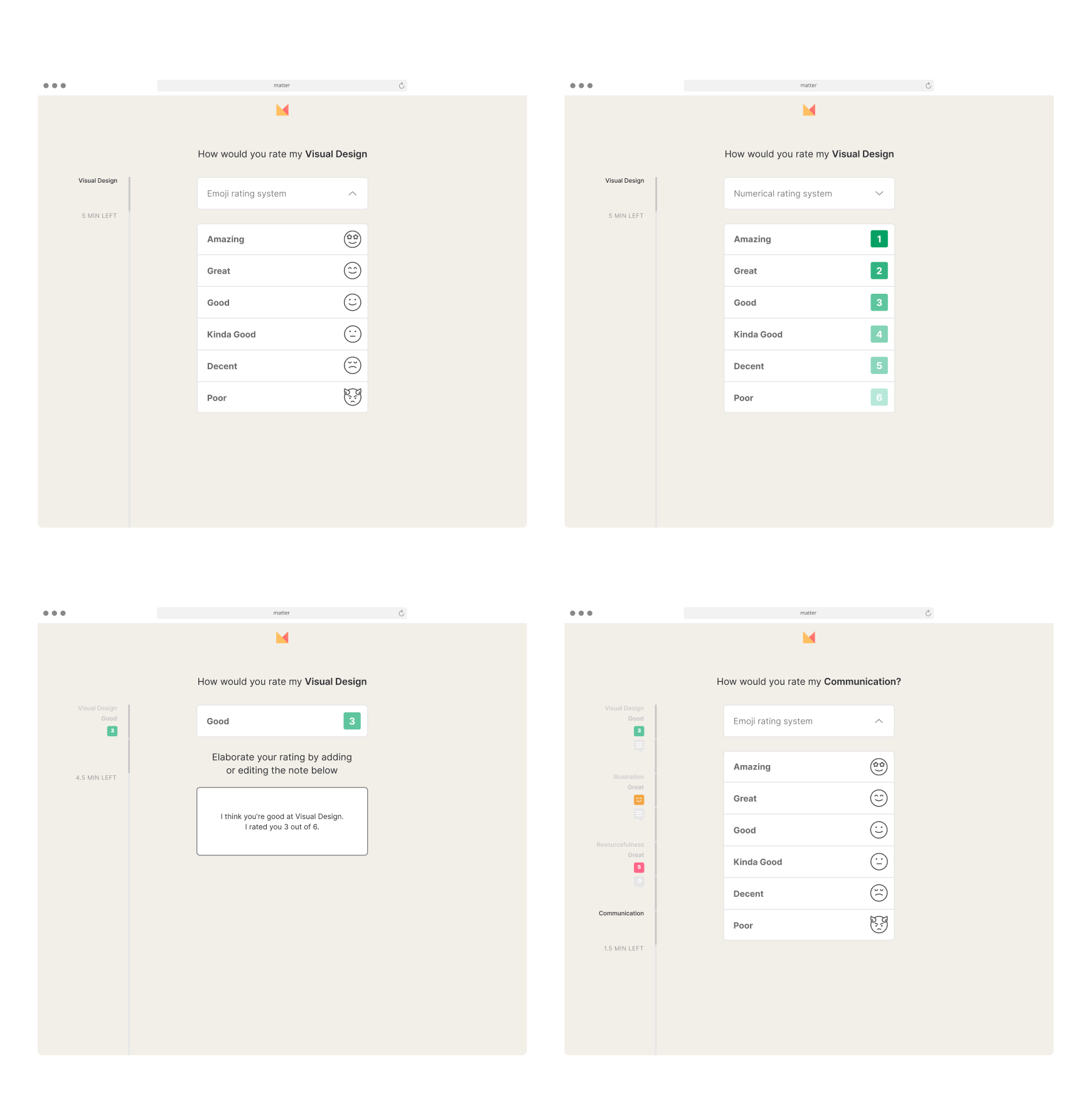
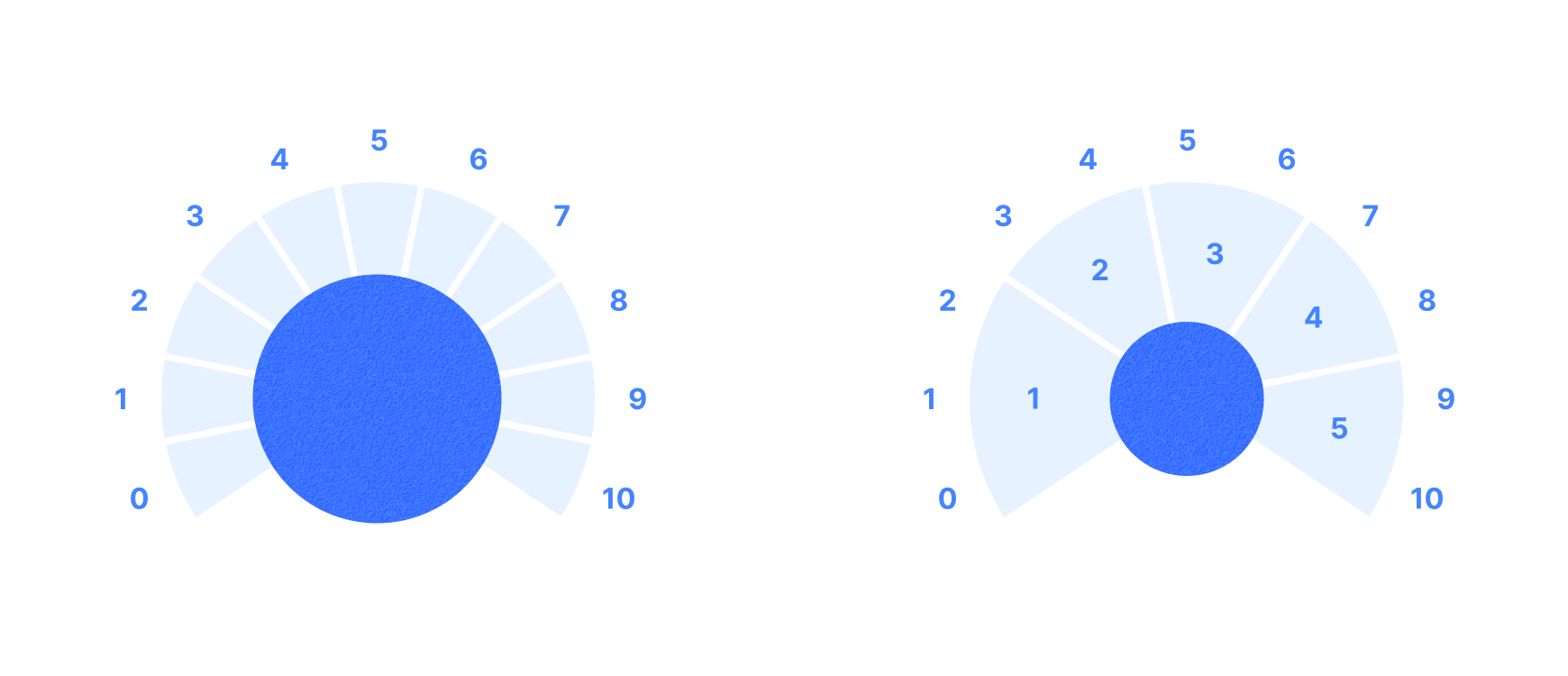
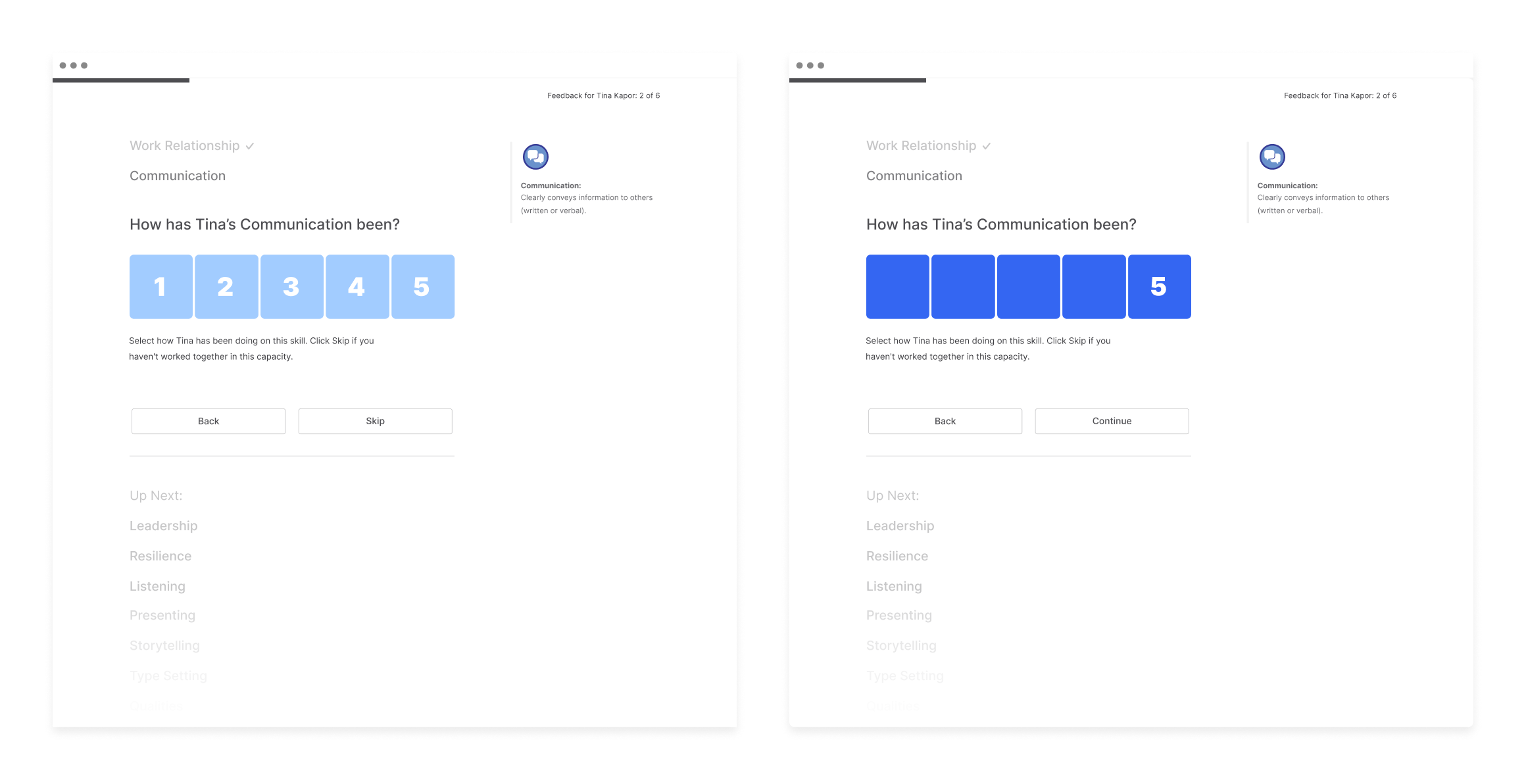
Then came the rating mechanism itself. Do we keep the current 10-step scale? Do we change it to a completely different system? Do we get rid of it completely and rely on written feedback exclusively?
We were able to throw this into scheduled IDI’s (in-depth interviews) with super-users and the results leaned in favor of a numerical rating system overall. The questioned still remained on whether we keep 10 as a max.
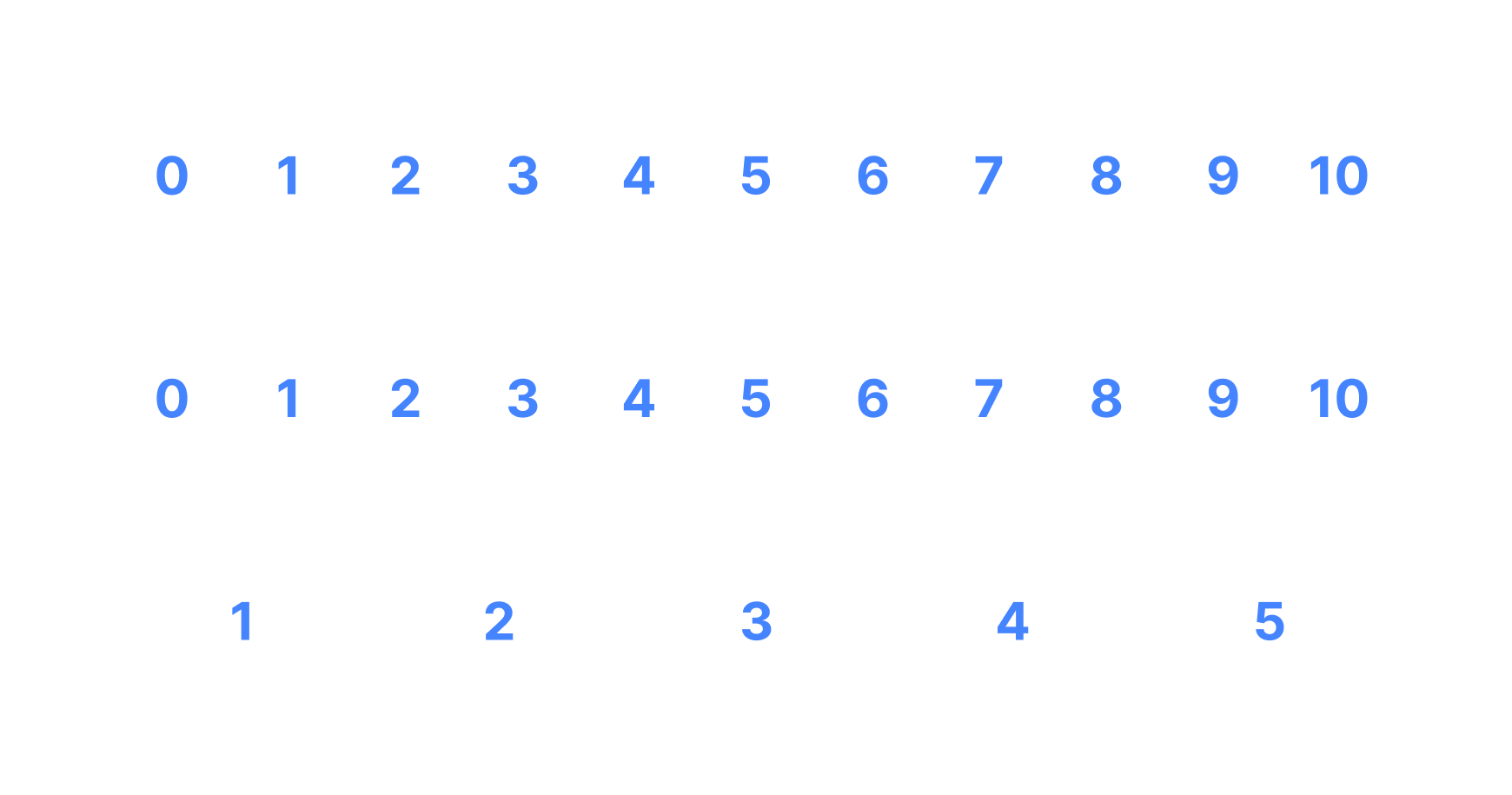
Everybody seemed to be on board with simplifying the rating system but what does that mean? Talking the engineers it seemed that our rating scale was actually 11 (0-10 instead of 1-10) but we could still do a max of 5 by grouping all the current ratings by 2, with the lowest one grouped by 3 ([0 through 2] = 1).
This resulted with the finalized system below (rough animatic).
There was a dissagreement with the rest of leadership on applying any additional illustrations or graphics for the initial launch. When it comes to testing and user metrics, it would be ideal for the data to be clean and factors like artwork (at least for the MVP), could muddy everything up.
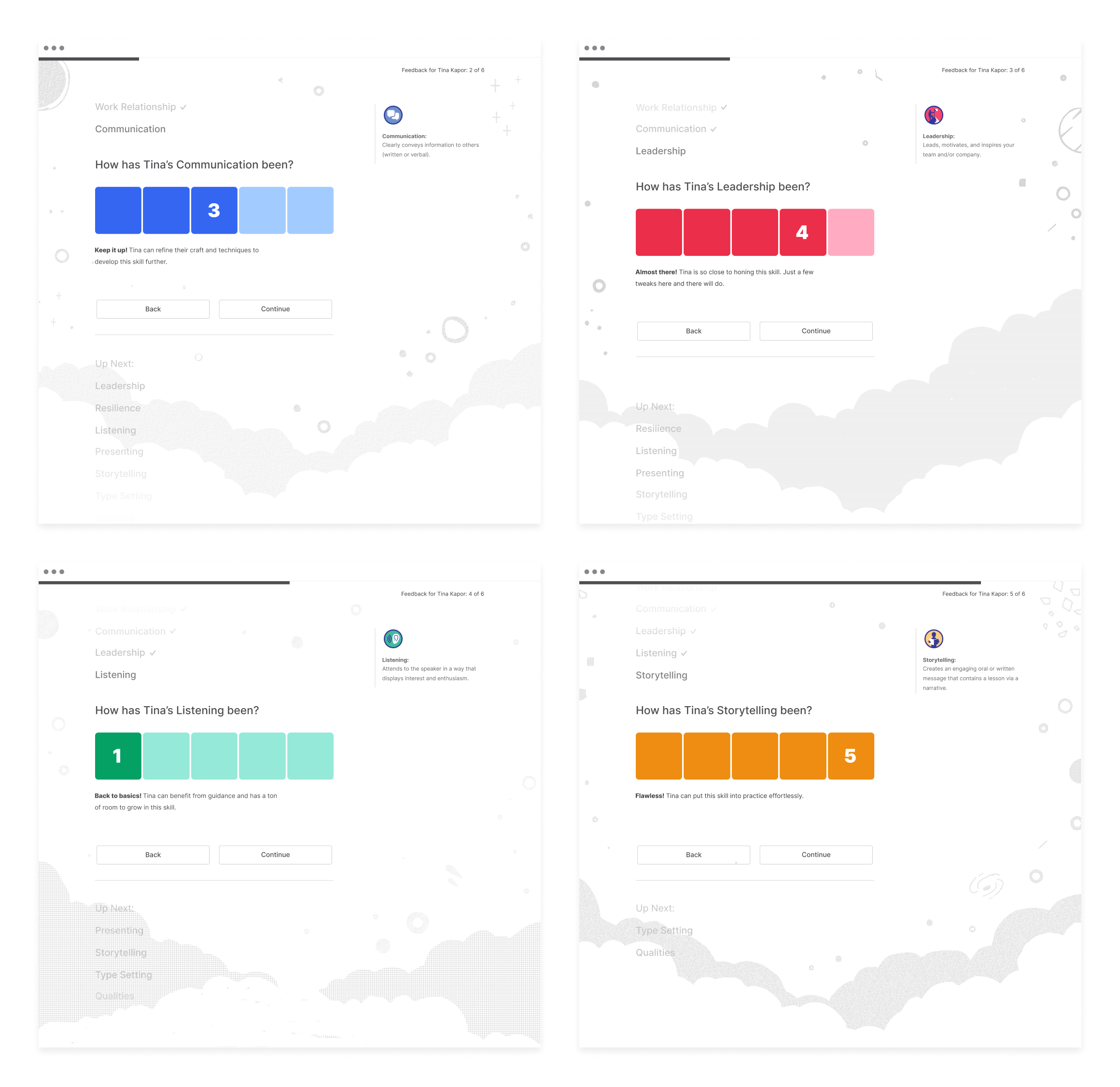
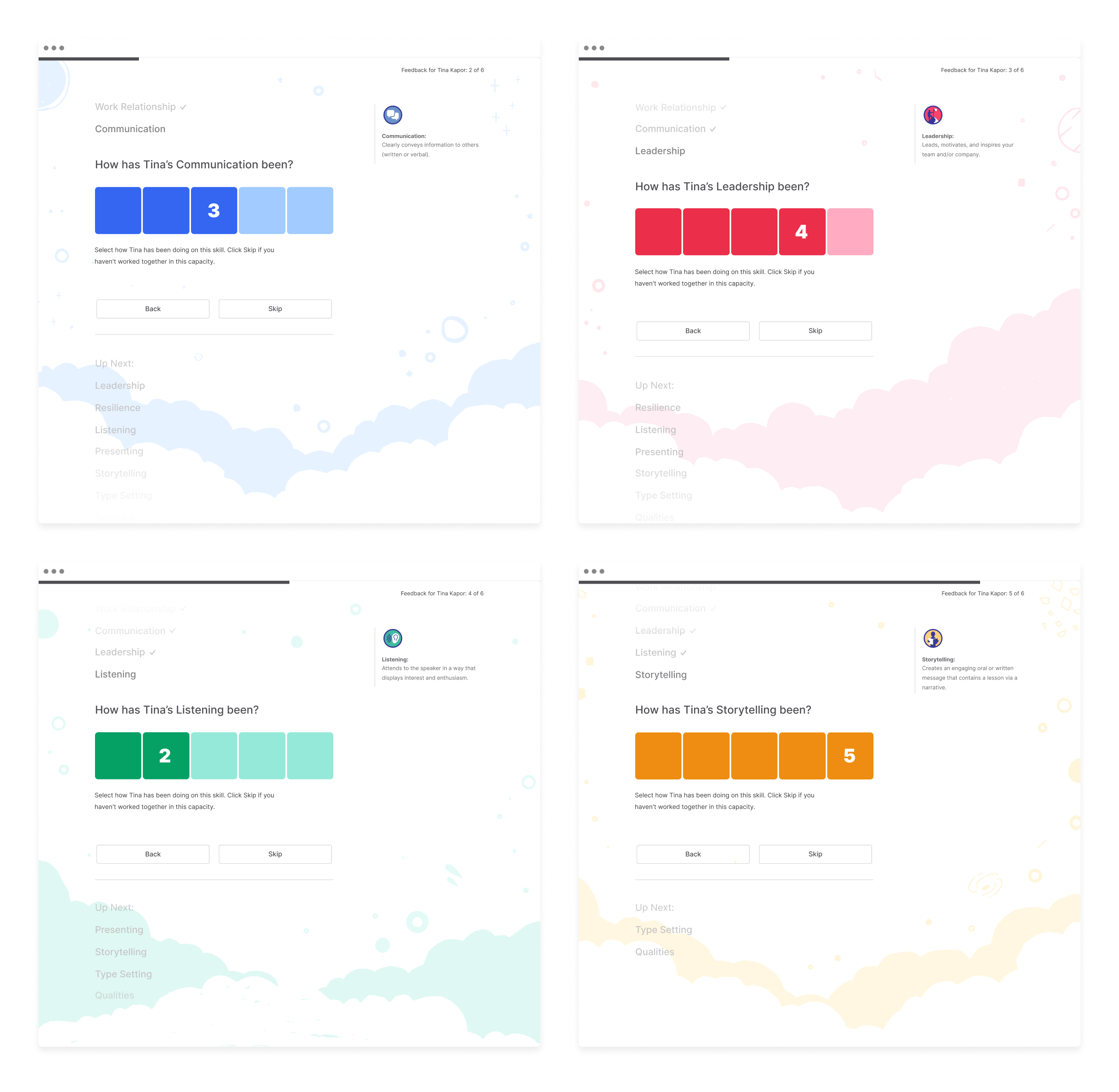
We ended up compromising on something that was already part of the current brand – a space theme.
We started producing seamless backgrounds using cloud-like shapes (image above), then started adding the space motifs that were being used in promotional materials (image below).
After testing various options for black and white vs color, it was down to two – colored pastels that went along with the skill color or pattern overlays.
The background needed to have just enough subtilty so that it didn’t become a problem and compete with the foreground elements. Instead, they needed to enhance the experience rather than overwhelm. With this mindset, the color was toned down.
It was my opinion that the pastels made everything feel very washed out so in the end we went with the patterns.